KubeBlocks 学习和调研报告
服务
非常专业,非常热情
安装
非常方便
基于 Kubernetes ,https://console.apecloud.cn 选择下面这个 KubeBlocks Anywhere
Kubeblock 会 询问你一些问题,然后引导你下载 YAML
运行kubectl apply -f [path to file]/openim-bootstrap.yaml在你的kubernetes集群上。
一旦安装了引导YAML文件,目标的状态将反映在状态面板中。一般需要1-2分钟完成注册。
速度非常快,没有障碍。
安装的步骤:
- [x] Kubernetes 的链接
- [ ] Kubeblocks 的链接
- [ ] 签入成功
为什么需要
我们知道,因为 OpenIM 的数据库非常多,现在为止,用到了 Mysql,Redis,Mongo
Kubernetes 最开始是并不合适做有状态数据库管理的。
Deployment 中滚动更新和升级中哪个 Pod 能下线是不能随便选择的,可能数据库有主从模式,这种场景下光靠 Deployment 自己就很难应对了。
虽然 Kubernetes 提供了另一个抽象方式,帮助我们应对其他一些用 Deployment 无法处理的应用编排场景,这个设计就是对有状态应用的管理,StatefulSet
Deployment 不足以颠覆所有的应用问题,deployment 对应用做了一个简单的假设,所有的应用 pod 都是一样的,相互之间没有顺序,也无所谓在哪台宿主机上运行。需要时 Deployment 就可以通过 Pod 模板创建新的 Pod 。不需要的时候可以随时终结一个 Pod。
但是分布式应用中,它的多个实例往往有多种关系,比如说 主从关系,主备关系;还有数据库存储类应用。它的多个实例往往会在本地磁盘上保存一份数据,而这些实例一旦被结束,即使重建出来,实例和数据之间对应的关系也已经丢失,导致应用失败。
所以说,实例之间有一种不平等的关系,以及实例对外部数据有依赖的应用,就称之为有状态应用。
Kubernetes 对 Deployment 基础上扩展了对有状态应用的基本支持,编排功能就是 StatefluSet
它抽象出来了两种情况:
- 拓扑结构:应用的多个实例之间不是完全对等的,这些实例必须要按照一定的优先级顺序启动,比如说 主节点A 要依赖 从节点 B 启动。
- 存储状态:应用的多个实例分别绑定了不同的存储数据。对于这些应用实例来说,Pod A 第一次读取到的数据和隔了 10 分钟之后再次读取到的数据应该是同一份,哪怕在此期间 Pod A 被重新创建过。
与云提供商集成的困难,缺乏可靠的运营商,以及学习的难度
K8S曲线KubeBlocks提供了一个开源选项,可以帮助应用程序开发人员和平台
工程师为RDBMS、NoSQL、流媒体和分析系统设置了功能丰富的服务。
不需要成为K8的专业人士,任何人都可以建立一个完整的堆栈,生产就绪型数据基础架构。
Enhanced stateful workloads
KubeBlocks扩展了K8的StatefulSet功能,支持ReplicationSet和PocksusSet工作负载。
他们知道数据库集群中的不同角色,并选择对业务连续性影响最小的最佳更新策略,监控数据复制状态并自动修复错误和延迟。
KubeBlocks处理复杂性,并为MySQL,PostgreSQL,Redis和MongoDB提供最先进的管理体验。
它提供了按需配置、扩展、监控、备份和恢复,降低了数据库管理的风险和从开发到生产所需的时间。
强大而直观的CLI
ClickOps以耗时和容易出错而闻名。KubeBlocks为生产力提供了kblog。您可以安装KubeBlocks,并使用单个命令在桌面或云端上启动游乐场环境。kbstrike简化了在Kubernetes中使用data infra的学习曲线。
KubeBlocks 解决了哪些问题(参考官方文档)
- https://kubeblocks.io/docs/preview/user_docs/overview/introduction
Kubernetes已经成为容器编排的事实标准。它通过ReplicaSet提供的可扩展性和可用性以及Deployment提供的推出和回滚功能来管理数量不断增加的无状态工作负载。
然而,管理有状态工作负载对Kubernetes提出了巨大的挑战。虽然StatefulSet提供了稳定的持久存储和唯一的网络标识符,但这些能力对于复杂的有状态工作负载来说还远远不够。
为了应对这些挑战,并解决复杂性问题,KubeBlocks引入了ReplicationSet和ReplicsusSet,具有以下功能:
- 基于角色的更新顺序可减少因升级版本、扩展和重新启动而导致的停机时间。
- 维护数据复制的状态并自动修复复制错误或延迟。
关键特征
- 兼容AWS、GCP、Azure和阿里云。
- 支持MySQL、PostgreSQL、Redis、MongoDB、Kafka等。
- 提供生产级性能、恢复能力、可扩展性和可观察性。
- 简化第2天的操作,如升级、扩展、监控、备份和恢复。
- 包含一个强大而直观的命令行工具。
安装 kbcup
只需要一条命令部署:
curl -fsSL https://kubeblocks.io/installer/install_cli.sh | bash
尝试KubeBlocks的最快方法是创建一个新的Kubernetes集群,并使用playground安装KubeBlocks。但是,生产环境更加复杂,应用程序运行在不同的命名空间中,并且具有资源或权限限制。
命令 kbcli kubeblocks install 在 kb-system 命名空间中安装KubeBlocks,或者您可以使用 --namespace 标志指定一个。
kbcli kubeblocks install
查看可用版本。
kbcli kubeblocks list-versions
使用 --version 指定一个版本并运行下面的命令。
kbcli kubeblocks install --version=x.x.x
验证:
kbcli kubeblocks status
除此之外,还可以 使用Helm安装KubeBlocks
如果你用Helm安装KubeBlocks,要卸载它,你也必须使用Helm。
helm repo add kubeblocks https://apecloud.github.io/helm-charts
helm repo update
helm install kubeblocks kubeblocks/kubeblocks \
--namespace kb-system --create-namespace
运行以下命令,检查KubeBlocks是否安装成功。
kbcli kubeblocks status
升级
升级对于用户来说是尤为重要的,我们来看下 kubeblocks 如何升级
KubeBlocks 0.6版本与0.5版本相比有许多图像更改。升级过程中,如果集群中有多个数据库实例,同时拉取镜像可能会导致实例长时间不可用。
链接数据库
在部署KubeBlocks并创建集群之后,数据库将作为Pod在Kubernetes上运行。您可以通过客户端接口或 kbcli 连接到数据库。如下图所示,您必须清楚连接数据库的目的。
- 要试用KubeBlocks并测试数据库功能,或使用低流测试进行基准测试,请参阅在测试环境中连接数据库。
- 若要在生产环境中连接数据库,或进行高流量压力测试,请参见在生产环境中连接数据库。
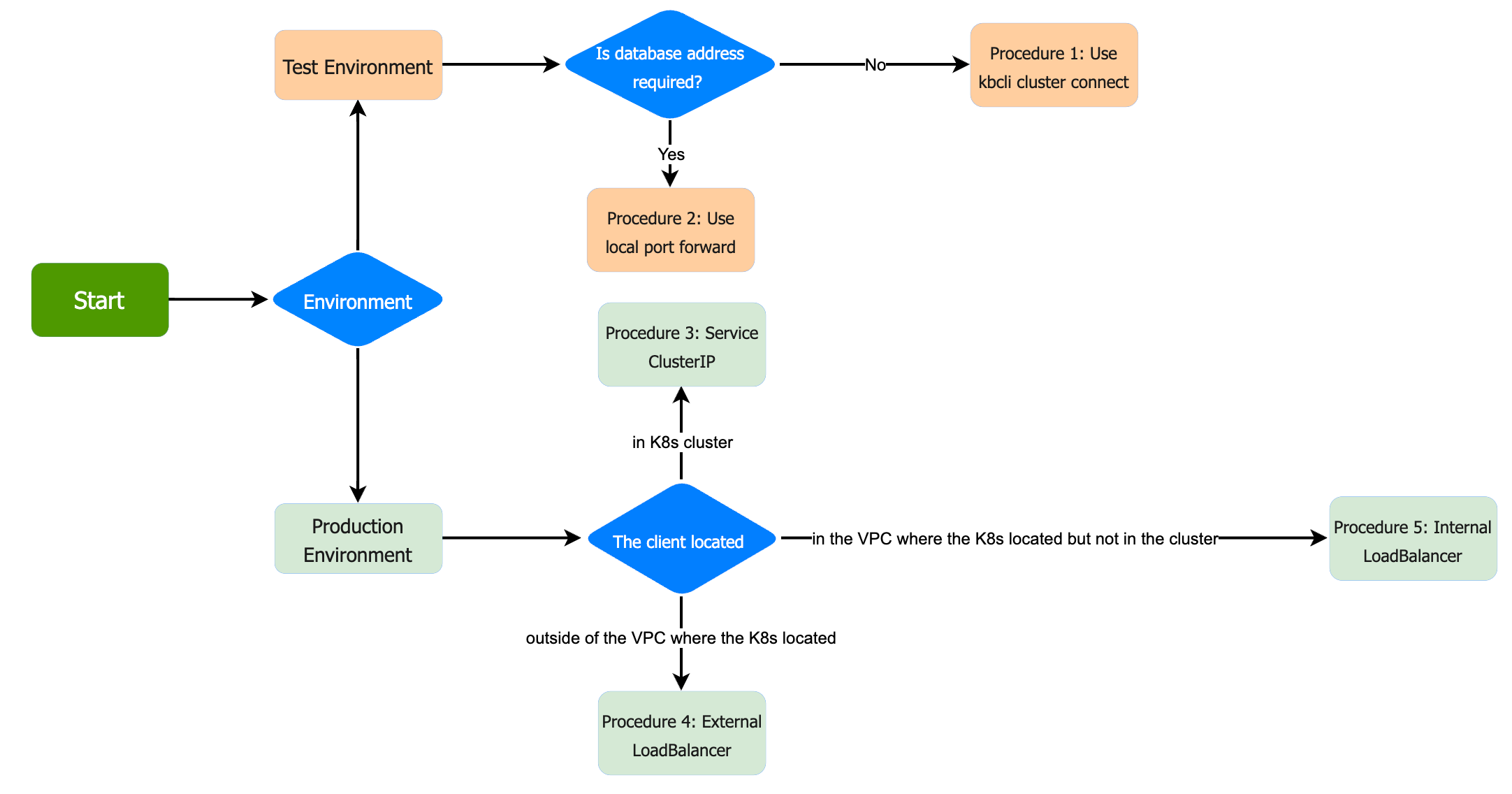
在测试环境中连接数据库
程序1.使用kblog cluster connect命令
您可以使用 kbcli cluster connect 命令并指定要连接的群集名称。
kbcli cluster connect ${cluster-name}
下面的命令实际上是 kubectl exec 。只要可以访问K8s API服务器,该命令就可以正常工作。
程序2.使用CLI或SDK客户端连接数据库
执行以下命令,获取目标数据库的网络信息,并使用打印的IP地址进行连接。
kbcli cluster connect --show-example ${cluster-name}
打印的信息包括数据库地址,端口号,用户名密码下图是MySQL数据库网络信息示例。
- 地址:-h指定服务器地址。在下面的示例中,它是127.0.0.1
- Port:-P指定端口号,在下面的示例中为3306。
- 用户名:-u是用户名。
- 密码:-p显示密码。在下面的例子中,它是hQBCKZLI。
密码不包括-p。
在生产环境中连接数据库
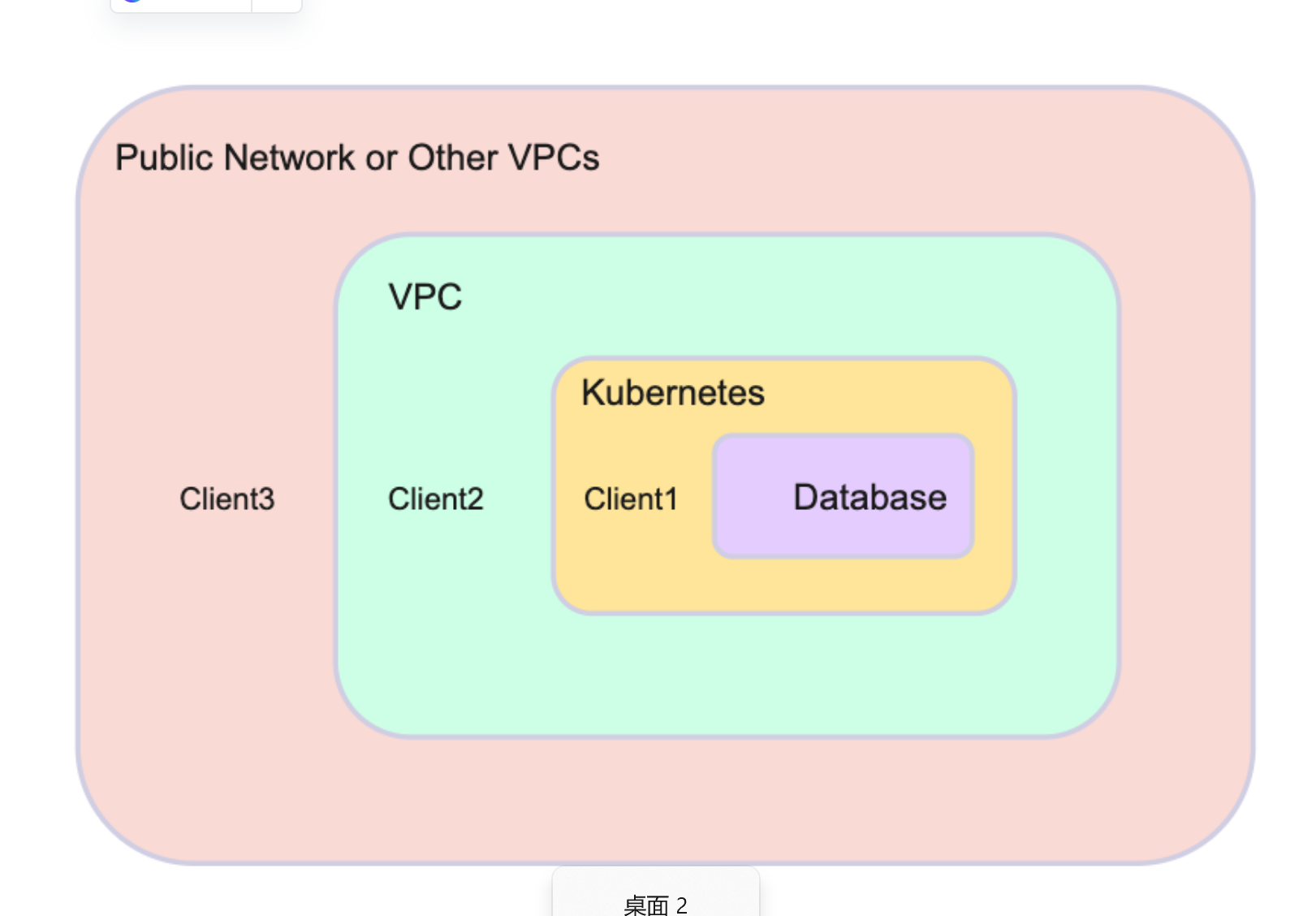
在生产环境中,通常使用CLI和SDK客户端连接数据库。有三种情况。
- 场景1:客户端1和数据库在同一个Kubernetes集群中。要连接client1和数据库,请参见过程3。
- 场景2:客户端2在Kubernetes集群之外,但与数据库在同一个VPC中。要连接client2和数据库,请参见过程5。
- 场景3:Client 3和数据库位于不同的私有网络中,例如其他私有网络或公网。要连接client3和数据库,请参见过程4。
请参阅下图以获得网络位置的清晰图像。
步骤3.连接同一Kubernetes集群中的数据库
您可以使用数据库连接的域名或网址。要检查数据库端点,请使用 kbcli cluster describe ${cluster-name} 。
kbcli cluster describe x
可观测性
通过内置的数据库可观察性,您可以观察数据库的健康状态,并实时跟踪和测量数据库,以优化数据库性能。本节向您展示数据库监控工具如何与KubeBlocks一起工作以及如何使用该函数。
KubeBlocks通过插件的方式集成了Prometheus、AlertManager、Grafana等开源监控组件,并采用自定义的 apecloud-otel-collector 来收集数据库和主机的监控指标。部署KubeBlocks Playground时,将启用所有监控附加组件。
KubeBlock Playground支持以下内置监控插件:
prometheus:它包括Prometheus和AlertManager附加组件。grafana:它包括Grafana监控插件。alertmanager-webhook-adaptor:它包含通知扩展插件,用于扩展AlertManager的通知功能。目前支持飞书、鼎Talk、WeChat企业号等自定义机器人。apecloud-otel-collector:用于收集数据库和主机的指标。
查看所有内置加载项并确保已启用监视加载项。
# View all add-ons supported
kbcli addon list
...
grafana Helm Enabled true
alertmanager-webhook-adaptor Helm Enabled true
prometheus Helm Enabled alertmanager true
...
查看仪表板列表。
kbcli dashboard list
>
NAME NAMESPACE PORT CREATED-TIME
kubeblocks-grafana kb-system 13000 Jul 24,2023 11:38 UTC+0800
kubeblocks-prometheus-alertmanager kb-system 19093 Jul 24,2023 11:38 UTC+0800
kubeblocks-prometheus-server kb-system 19090 Jul 24,2023 11:38 UTC+0800
打开并查看监控仪表板的Web控制台。比如说,
kbcli dashboard open kubeblocks-grafana
启用监控功能
KubeBlocks提供了一个插件 victoria-metrics-agent ,用于将监控数据推送到与Prometheus远程写入协议兼容的第三方监控系统。与原生的Prometheus相比,vmgent更轻,支持水平扩展。
启用数据推送。
您只需提供支持Prometheus远程写入协议的端点,即可支持多个端点。有关如何获取端点的信息,请参阅第三方监控系统的教程。
下面的示例显示了如何通过不同的选项启用数据推送。
# The default option. You only need to provide an endpoint with no verification. # Endpoint example: http://localhost:8428/api/v1/write kbcli addon enable victoria-metrics-agent --set remoteWriteUrls={http://<remoteWriteUrl>:<port>/<remote write path>}(可选)水平缩放
victoria-metrics-agent附加组件。当数据库实例数量持续增加时,单节点虚拟机成为瓶颈。这个问题可以通过缩放vmagent来解决。多节点虚拟机根据Hash策略自动划分数据采集任务。
kbcli addon enable victoria-metrics-agent --replicas <replica count> --set remoteWriteUrls={http://<remoteWriteUrl>:<port>/<remote write path>}(可选)禁用
victoria-metrics-agent加载项。kbcli addon disable victoria-metrics-agent
观察MySQL集群
KubeBlocks支持完整的可观察性功能。本节演示KubeBlocks的监控功能。
步骤:
打开grafana仪表板。